그리고 조건문이 있다면 조건문의 실행 시간을 전부 더한 것을 C라고 생각하면 시간 복잡도는 O(C*n)이다.
하지만 시간 복잡도는 상수를 무시한다. 즉, O(n)이다.
간혹 가다 log가 나오는데 이것은 보통 $log_2$이다.
몇 가지 수학적 지식이 들어가는데 그냥 2로 나누면서 반복문을 돌렸을 때 나온다?라고 생각하면 된다.
더 깊이 들어가기 싫다!!!!!!!!! 수학 멈춰!!!!!!!!!!!!!!!!!
시간 복잡도의 표현중에서도 표기법이 다르다.
"빅-오 표기법, 오메가 표기법, 세타 표기법"이 있는데 차례로 최악, 최상, 평균이다.
퀵 소트랑 머지 소트는 시간 복잡도가 어떻게 되는 걸까?
정렬 종류
평균
최선
최악
퀵소트
$O(nlogn)$
$O(nlogn)$
$O(n^2)$
머지소트
$O(nlogn)$
$O(nlogn)$
$O(nlogn)$
자 위의 표를 보면 최대한 시간 복잡도가 좋은 것을 사용해야 최고의 방법을 찾지 않을까 한다.
퀵 소트에 대해 자세히 알아보자!
퀵 소트는 pivot을 기준으로 두 개의 구역으로 나눠서 pivot의 정확한 위치를 알게 하는 것이 첫 번째 목표이다.
많은 요소가 존재할 때를 생각해보면 처음에는 pivot을 1개로 잡고 분리 진행한 후 pivot을 정확한 위치에 존재하게 한다.
그리고 두 개의 구역으로 존재한 각각의 구역에서 각각의 pivot을 잡고 그 두 개의 pivot을 정확한 위치에 존재하게 한다.
이 과정을 반복한다면 마지막엔 결국 n개의 구역에 있는 원소가 1개가 되는데 이때 정렬이 완료가 된다.
우리가 이 부분에서 확실히 구현 가능한 부분은 pivot의 위치를 고정한다. 그리고 거의 마지막 과정(즉, 5개 이하의 원소가 남았을 때)에서는 정렬시킬 수 있다.
우리가 생각해봐야 할 것은 두 개의 deque으로 구현해야 하기 때문에 구현 과정은 거의 2 개의 서브 노드가 독립적인 이진트리와 같은 형상으로 구현되어야 한다는 것이다.
작성하는 걸 까먹었다... ㅋㅋ
전체적으로 진행되는 방법에 대해서만 쓰겠다.
입력인자를 받아 에러 체크를 한다.
입력인자들을 deque a에 차곡차곡 쌓는다.
정렬된 배열 sorted를 quick sort로 생성한다.
deque a의 size를 판단하고 5개 이하면 내가 작성한 로직대로 진행한다.
5개 이상이면 a_to_b로 가서 pivot 2개를 생성한다.(이때 pivot을 잡는 방법은 정해진 size에서 sorted에서 3등분을 해서 2개를 잡는다.)
a_to_b에서는 큰 pivot보다 크거나 같을 때 a의 뒤로 보낸다.
작은 pivot보다 작거나 같으면 b로 보낸다.
큰 pivot보다 작지만 작은 pivot보다 크다면 b로 보낸뒤 뒤로 보낸다.
다 했다면 a, b에서 뒤로 보냈던 인자들을 복구한다.
그리고 a_to_b, b_to_a, b_to_a로 선언한다.
b_to_a는 a_to_b와 같이 pivot을 2개 생성한다.
작은 pivot보다 작거나 같으면 b의 뒤로 보낸다.
큰 pivot보다 크다면 a로 보내고 뒤로 보낸다.
작은 pivot보다 크고 큰 pivot보다 작거나 같으면 a로 보낸다.
a_to_b로 보낸다.
다했다면 a, b에서 뒤로 보냈던 인자들을 복구한다.
a_to_b, b_to_a를 선언한다.
이때 a_to_b와 b_to_a에서 size가 3개 이하라면 내가 따로 작성한 로직대로 진행하도록 한다.
이것이 끝이다.
여기서 조금 주의해야 할 것은 Error의 출력은 표준에러로 출력해야 한다는 점이다.
그리고 우리가 생각해봐야할 것은 rr, ss, rrr의 사용은 기본이지만 연속해서 나오는 명령어들이라는 것이다.
예를 들어 sa이후 sa가 나온다면 굳이 표시하지 않아도 된다. 이런 경우를 생각해봤을 때, 나는 내 로직에서 나오는 명령어들에서 r이후 rr의 명령어가 가장 많이 나오는 것으로 분석했고 ra 이후 rra가 나오거나 rb 이후 rrb가 나오는 경우에 명령어를 생략하기로 했다.
3.bonus
bonus는 제공하는 checker의 작성이다.
사실 checker의 로직에서는 특별히 사용될 함수는 read뿐이다.
즉, 우리가 push_swap에서 사용했던 함수를 조금 수정하고 get_next_line를 가져와서 사용하면 되는 것인다.
이번에 Norm의 버전이 바뀌어서 새로 작성하기로 했다.
시험에서의 get_nest_line과 유사하게 표준입력(fd=0)으로 받고 종료되었다면 끝내고 정렬이 되었는지 확인하는 것이다.
표준입력으로 받고 개행문자(\n)로 받았다면 그 이전까지 보내준다. 그리고 명령어들을 확인하고 수행해준다. 명령어중에 속한것이 없다면 Error를 표준에러로 출력한다.
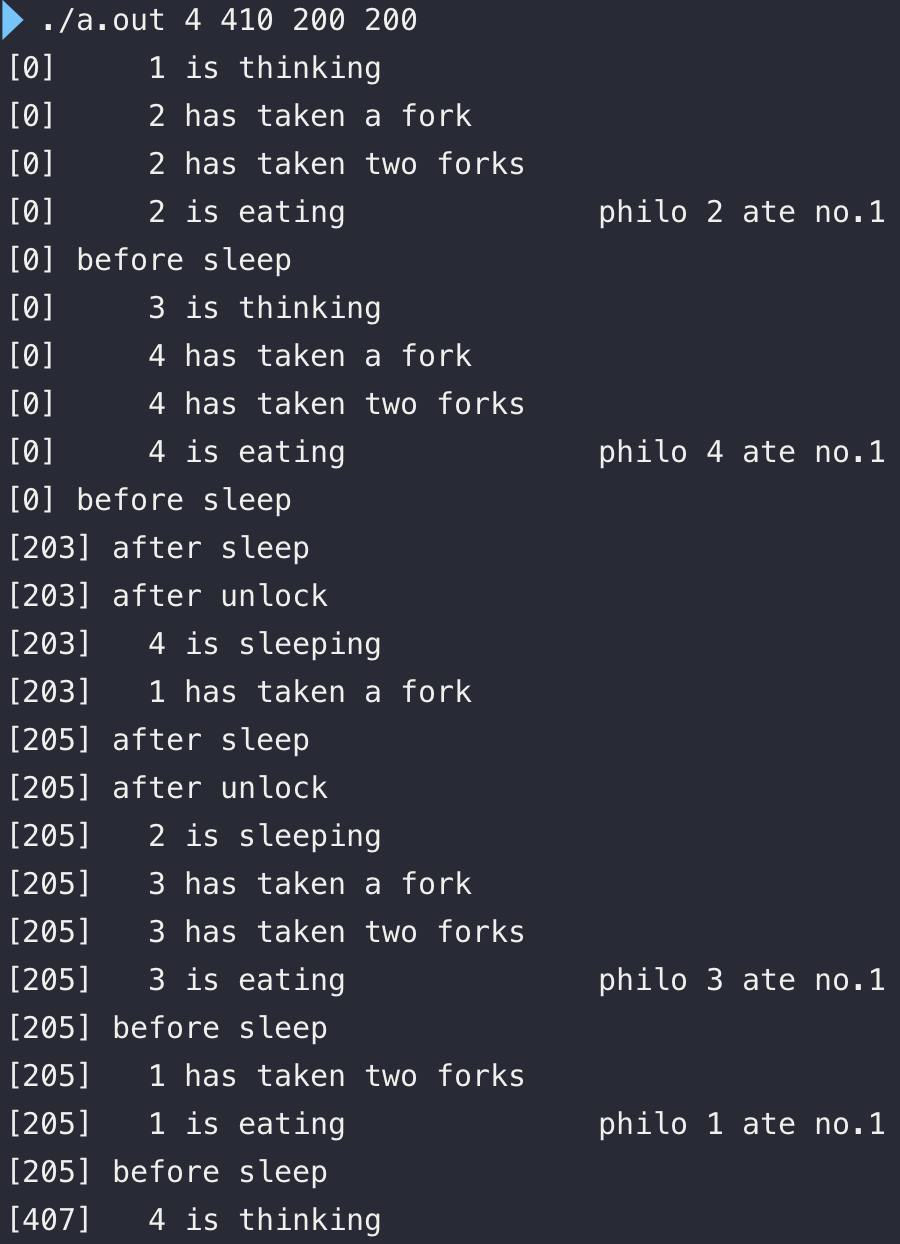
프로세스가 시그널을 받게 되면 해당하는 기본적인 동작을 하거나, 무시하거나, 내가 정의한 함수를 통해 동작 방식을 바꿀 수 있다.
프로세스가 시그널을 받게 되었을 때, 보낸 곳에서 시그널을 제대로 받았는지 확인하지 않는다.
시그널을 처리 중일 때 다른 시그널을 받게 되면 무시된다.
시그널을 발생시키는 번호에서 SIGSTOP과 SIGKILL은 시그널을 받으면 프로세스를 멈추고 죽이는 것인데 우리가 사용하는 SIGINT처럼 제어할 수 있는 것이 아니다.
내가 본 과제에서 해야 할 것과 진행 과정을 알아보자!
우리는 client 와 server를 만들어야 하는데 이 둘은 서로 통신이 가능해야 한다.
시작할 때 server가 먼저 실행된 후에 client가 실행되어야 하는데
client가 실행되었을 땐 본인의 pid를 출력하고
입력 파라미터로 server의 pid와 전달할 문자열이 입력되어야 한다.
또한, server는 문자열을 전달받으면 출력해야 한다.
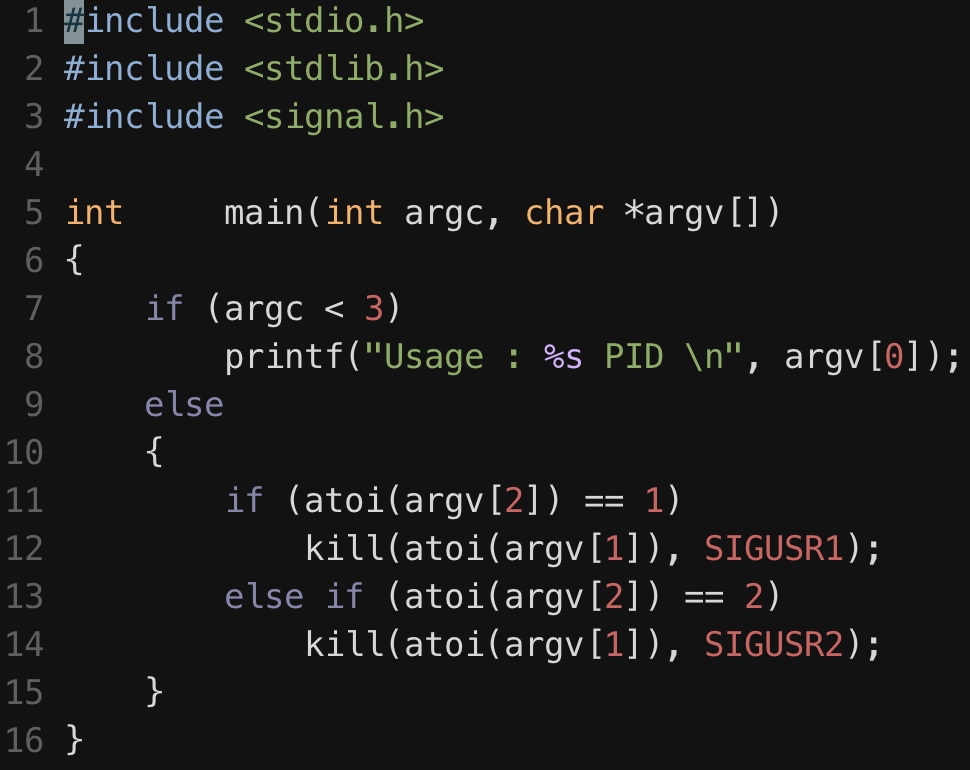
여기서 우리는 SIGUSR1과 SIGUSR2만 사용할 수 있다.
SIGINT, SIGQUIT등의 문자는 사용이 불가한 건가..?
진행함에 앞서 몇가지 실험을 해보자
실행중인 프로세스을 kill하는 예제이다.
카운트 다운kill
위와 같은 결과로 실행중인 프로세스를 kill하는 법을 알아간다.
여기서 우리가 알수 있는 것은 하나의 프로세스에 signal을 주는 것은 이렇게 만들수 있다는 것이다.
두번째
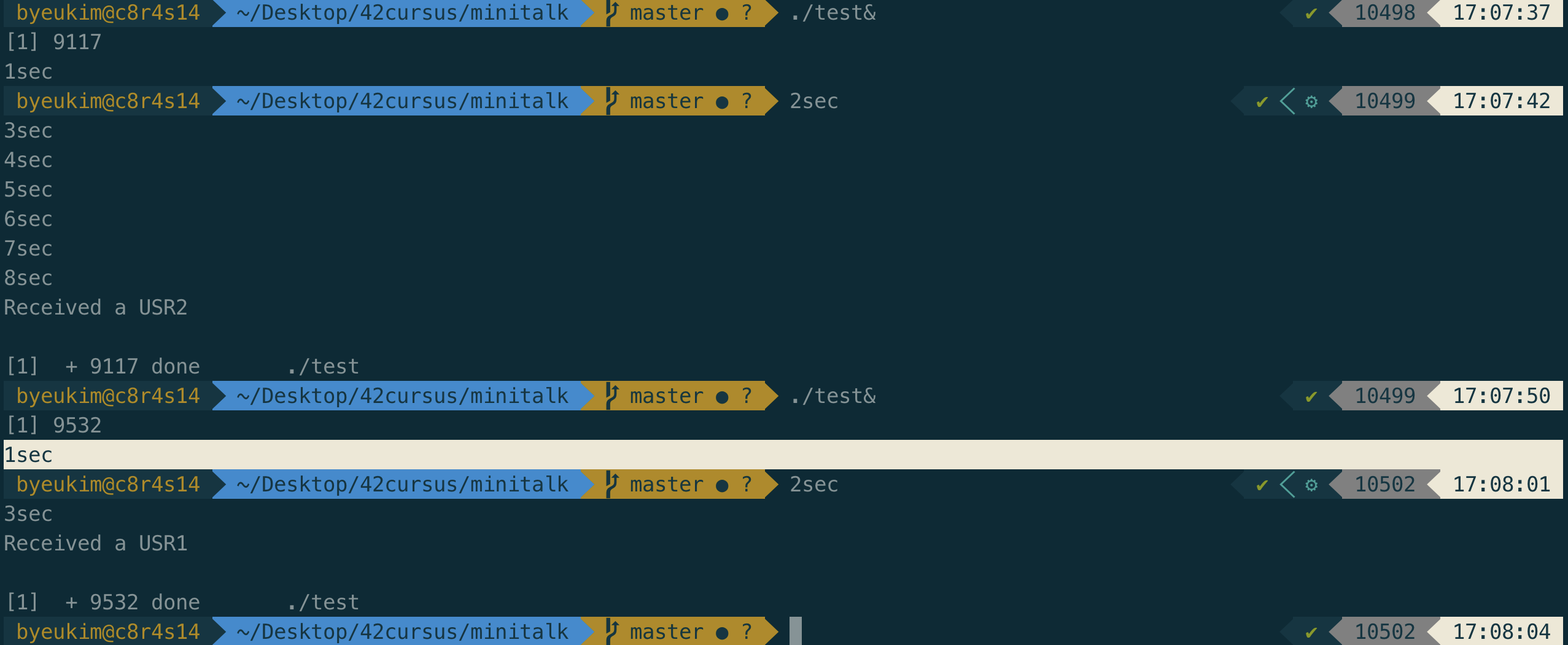
SIGUSR1과 SIGUSR2를 사용하는 방법이다.
SIGUSR1, SIGUSR2 테스트SIGUSR1, SIGUSR2의 signal 전달
위의 결과로 나온다.
우리는 SIGUSR1과 SIGUSR2를 이용해서 signal을 줄 수 있는 방법을 알았다.
그렇다면 이제 SIGUSR1와 SIGUSR2를 어떤 식으로 사용을 할 수 있을까?
그 전에 우리가 한가지 알아야 할 점이 있다.
signal과 sigaction은 기능이 비슷하다.
그래서 찾아보면 signal은 핸들러를 구축하는 오래되고 간단한 방법이지만 더이상 사용하지 않는다.
그 이유는 무엇이냐!
Unix에서 시그널을 받은 후에 디폴트 값으로 핸들러를 리셋해버리기 때문이다. 만약 죽는 프로세스를 잡기 위해 SIGCHLD 각각을 별도로 핸들링 할 필요가 있는 경우 경쟁이 필요하다. 이 때문에 핸들러 내부에 핸들러를 설정할 필요가 있으며 signal을 호출하기 전에 다른 시그널이 도착할 것이다. 사실 진행중인 프로젝트에는 그렇게 연관성이 있는지 모르겠고 구현이 signal로도 충분히 될 것이라 생각이 든다.
하지만, 현재 사용할 수 있는 함수 중 sigaction을 주었기에 사용하여 구현하는 것이 프로젝트가 원하는 바라고 생각이 든다.
원래는 800X600의 window에서 마우스의 좌표를 가져오는데 mandelbrot set은 표현되는 범위가 Real : (-2, 1), Imaginary : (-1, 1)이므로 축소를 시켜줘야 한다.
즉, 이렇게 축소시켜주는 단계에서 화면에 나타날 이미지의 크기가 지정되어있었다.... 꺾꺾꺾
완전히 갈아엎었다.
이전에는 mandelbrot을 계산하는 곳에서 좌표를 계산했지만 지금 작성한 로직은 스크롤을 하면 x, y의 좌표가 움직이지 않고 똑같이 그대로 있어야 한다는 생각이 base로 잡혔고 그에 따라 계산하는데 zoom의 비율은 현재 상태에서 0.1씩 증가하고 감소하게 작성했으며 픽셀의 색을 정하는 첫 시작인 $c_{re}$ 와 $c_{im}$가 $width_{min} , height_{min}$ 이 되게 만들었다.
이제 여기서 생각해봐야 하는 점은 우리가 x, y 좌표를 그대로 유지시키면서 어떻게 $c_{re}$ 와 $c_{im}$를 변화시킬 것인지 생각해봐야 한다.
결국 도달한 결론은 아래와 같다. 글씨 못씀 주의
그리고 우리는 이런 결과를 볼 수 있게 된다.
아주 기괴하고 요상한 그림이 되어 버린다.
정말 뿌듯하다...
6. Julia set 심화
여기에서는 julia set에서의 고정값 c를 마우스의 좌표로 지정하여 형태를 변형시키는 방법을 진행할 것이다.
처음에 우리가 해야 할 것은 마우스의 모션을 감지하는 hook을 만들고 mouse_move라는 함수를 만들면서 마우스의 좌표(800x600)를 실제 좌표계의 좌표(4x4)로 변환하는 작업을 거쳐야 한다.
이 과정은 간단하게 생각해서 일차함수의 좌표변환과 같다.
우리가 받아오는 좌표의 원점은 왼쪽 위의 꼭짓점이다.
그래서 원점을 중앙으로 만들어준 뒤 800의 width를 4로, 600의 height를 4로 표현해주면 된다.